目录
- 命名捕获组
- 重复
- 重复次数表
- 元字符表
- 特殊符号表
- 环视结构表
- 匹配优先量词 (贪婪模式)
- 忽略优先量词 (懒惰模式)
- 占有优先量词 (侵占模式)
- 元字符
- 任意字符(
.) - 行的开始(
^) - 行的结束(
$) - 连字符(
-) - 字符组(
[...]) - 排除型字符组(
[^...]) - 多选结构 (
|) - 括号(
()) - 分组提取文本(
()) - 分组但不捕获(
(?:...)) - 转义 (
\) - 反向引用
- 引号内的字符串
- 环视结构
- 肯定型顺序环视 (左→右)
- 肯定型逆序环视 (左←右)
- 环视不会占用字符
- 肯定型顺序环视示例
- 固化分组 (?>...)
- 拆分正则表达式
- PHP正则
- 字符缩略表示法
- 字符组及相关结构
- 几乎任何字符 点号
- 字符组缩略表示法
- Unicode属性和区块
- 锚点及其他零长度断言
- 模式修饰符
- PHP Preg 函数概览
- 正则示例
- 匹配HTML标题
- 匹配时间
第三版
命名捕获组

元字符表
| 元字符 | 名称 | 匹配对象 |
|---|---|---|
. |
点号 | 单个任意字符(不包括换行) |
[...] |
字符组 | 列出的任意一个字符 |
[^...] |
排除型字符组 | 未列出的任意一个字符 |
^ |
脱字符 | 行的起始位置 |
$ |
美元符 | 行的结束位置 |
\< |
反斜线-小于 | 单词的起始位置 某些版本不支持 |
\> |
反斜线-大于 | 单词的结束位置 某些版本不支持 |
| |
竖线 | 匹配分隔两边的任意一个表达式 |
(...) |
括号 | 限制竖线的作用范围 |
重复

重复次数表
| 字符 | 次数下限 | 次数上限 | 含义 |
|---|---|---|---|
? |
0 | 1 | 可以不出现,也可以只出现一次 (单次可选) |
* |
0 | ∞ | 可以出现无数次,也可以不出现 (任意次数均可) |
+ |
1 | ∞ | 可以出现无数次,但至少要出现一次 (至少一次) |
{n,m} |
n | m | 能够容许的重现次数在n到m之间 |
{n,} |
n | ∞ | 能够容许的重现次数在n个以上 |
特殊符号表
| 符号 | 释义 |
|---|---|
\0 |
空字符 |
\t |
制表符 |
\n |
换行符 |
\r |
回车符 |
\s |
任何“空白”字符 (例如空格符、制表符) |
\S |
除\s之外的任何字符 |
\w |
[a-zA-Z0-9] |
\W |
除\w之外的任何字符,也就是[^a-zA-Z0-9] |
\d |
[0-9],即数字 |
\D |
除\d外的任何字符,也就是[^0-9] |
环视结构表
| 类型 | 正则表达式 | 匹配成功的条件 |
|---|---|---|
| 肯定逆序环视 | (?<=...) |
子表达式能够匹配左侧文本 |
| 否定逆序环视 | (?<!...) |
子表达式不能匹配左侧文本 |
| 肯定顺序环视 | (?=...) |
子表达式能够匹配右侧文本 |
| 否定顺序环视 | (?!...) |
子表达式不能匹配右侧文本 |
匹配优先量词(贪婪模式)
*+?{num,num}
忽略优先量词 (懒惰模式)
量词符号后加上
?
*?+???{num, num}?
量词在正常的情况下都是匹配优先的,匹配尽可能多的内容。 相反这些忽略优先的量词会匹配尽可能少的内容,只需要满足下限,匹配就能成功。
占有优先量词 (侵占模式)
量词符号后加上
+
*+++?+{num, num}+
类似普通的匹配优先量词,不过他们一旦匹配某些内容,就不会“交还”。类似固化分组。
元字符
如果将正则表达式当为普通的程序语言的话 元字符可以理解为语法。具有语法含义的字符。
.
匹配任意字符的占位符
点号,它在通常情况下不能匹配换行符,而排除型字符组[^*]通常都可以。
题目: 需要搜索03/19/76、03-19-76、03.19.76
答案: 03[-./]19[-./]76
^
行的开始
$
行的结束
连字符(-)
只有在字符组内部
-才是元字符表示一个范围 ,否则只是普通的连字符
- 如果连字符出现在字符组的开头,则
-只表示普通的字符 H[123456]等价于H[1-6][0123456789abcdefgABCDEFG]等价于[0-9a-gA-G]等价于[A-G0-9a-g]顺序无所谓- 在字符组内部
*永远都不是元字符
字符组([...])
字符组的内容是在同一个位置能够匹配的若干字符,所以它的意思是“或”。
列出期望匹配的字符,只能匹配[]中的一个。
排除型字符组([^...])
匹配一个未列出的字符
[^1-6] 匹配除了1到6以外的任意字符 ,但这种说法更好 ==匹配一个未列出的字符== 。
一个字符组,即使是排除型字符组,也需要匹配一个字符。
在字符组里面元字符的意义是不一样的:
[.]这里面的.就是 普通的.- 如果连字符
-不在字符组的开头 就是表示范围的
多选结构 (|)
gr[ea]y 与 gr(a|e)y 的例子可能会让人觉得多选结构与字符组没有多大的区别,但请留神不要混淆这个概念。
一个字符组只能匹配目标文本的单个字符 而每个多选结构自身都可能是完整的正则表达式 都可以匹配任意长度的文本
exmp:
^From|Subject|Date: 和 ^(From|Subject|Date):
左边匹配 ^From 或 Subject 或 Date:
右边匹配 From: 或 Subject: 或 Date: 开头的文本行
exmp:
this and | or that
等价于: (this and) | (or that)
不等于: this (and | or) that
虽然 and | or看上去是一个单位
括号(())
- 限制多选项的范围
- 将若干字符组合为一个单元,受量词的作用
- 反向引用
在一个表达式中我们可以使用多个括号,再用
\1,\2,\3等来表示第一、第二、第三组括号匹配的文本。
反向引用举例:
正则: ([a-z]+) +\1`
test test
the theory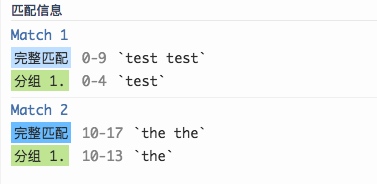
转义 (\)
它作用的元字符会失去特殊含义
大多数成与设计语言和工具都支持字符组内部的转义,但是大多数版本的egrep不支持,它们会把反斜线\当成字符组内部列出的普通字符。
反向引用
在支持反向引用的工具软件中,括号能够记忆其中的子表达式匹配的文本,不论这些文本是什么,元字符序列\1都能记住它们。
当然,在一个表达式中我们可以使用多个括号。再用\1 \2 \3等来表示第一、第二、第三组括号匹配文本
正则: ([a-zA-Z]+) \1
待匹配文本: the the
引号内的字符串
"[^"]*"
分组,但不捕获
(?:...)
环视结构
不匹配任何字符,只匹配文本中的特定位置。
肯定型顺序环视 (左→右)
(?=...)
eg: (?=\d) 表示如果当前位置右边的字符是数字则匹配成功
肯定型逆序环视 (左←右)
(?<=...)
eg: (?<\d) 表示如果当前位置的左边有一位数字,则匹配成功
环视不会占用字符
表达式Jeffrey匹配:
...by Jeffrey Friedl
同样的正则表达式,如果使用顺序环视功能,(?=Jeffrey),则匹配标记的位置·:
...by ·Jeffrey Friendl
只寻找能够匹配的位置,而不占用字符。把顺序环视和真正匹配字符的部分Jeff结合起来(?=Jeffrey)Jeff:
...by Jeffrey Friedl
下面的情况不会被匹配到
...by Thomas Jefferson
因为不存在(?=Jeffrey)能够匹配的位置,受此启发(?=Jeffrey)Jeff和Jeff(?=rey)等价。但顺序很重要
肯定型顺序环视示例
298,444,215
左边有字符,右边数字个数是3的倍数
(?<=\d)(?=(\d\d\d)+)
固化分组 (?>...)
/i.*!/能够匹配 iHola!
但是如果 .* 在固化分组中 /i(?>.*)!/ 就无法匹配 iHola! 。
在这两种情况下.*都会首先匹配尽可能多的内容Hola!。
但是之后的!无法匹配,会强迫.*释放之前匹配的某些内容(最后的!)
如果使用了固化分组,就无法实现。
因为.*在固化分组中,它永远也不会“交还”已经匹配的任何内容。
提高匹配效率,对什么能匹配,什么不能匹配进行准确的控制。
拆分正则表达式
多个小正则表达式比一个大正则表达式要快的多
因为对后者来说,不存在匹配成功必须的文字内容,所以不能进行内嵌文字字符串检查优化 大而全的正则表达式必须在目标文本中的每个位置测试所有的自表达式 速度相当慢
PHP正则
字符缩略表示法
\a\b退格\eesc\f\n换行\r回车\t制表符
字符组及相关结构
[](肯定断言 他们必须匹配一个字符)[^](匹配未列出字符的字符组)
[^LMNOP] 等价于 [\x00-kQ-\xFF] 但不是完全等价于。因为 : [^LMNOP] 可能包括成千上万个字符 只是不包含 L M N O P
几乎任何字符 点号
Unicode 混合序列 \x
可以视为点号的扩展 匹配一个基本字符 (除\p{M}之外的任何字符)
字符组缩略表示法
\w[a-zA-Z0-9_]\d[0-9]\s[ \f\n\r\t\v] 空白字符\W[^\w]\D[^\d]\S[^\s]
Unicode属性和区块 \p{Prop} \P{Prop}
单个字节(可能有危险)\C
()分组提取文本 (?:)分组但不提取文本
锚点及其他零长度断言
- 行、字符串起始位置
^\A - 行、字符串结束位置
$\z\Z - 当前匹配的起始位置
\G(或者是上一次匹配的结束位置) - 单词分界符
\b\B - 环视结构
(?=...)(?!...)(?<=...)(?<!...)
模式修饰符

PHP Preg 函数概览
| 函数 | 解释 |
|---|---|
preg_match |
测试正则表达式能否在字符串中找到匹配 并提取数据 |
preg_match_all |
从字符串中提取数据 |
preg_replace |
在字符串的副本中替换匹配的文本 |
preg_replace_callback |
对字符串中的每处匹配文本调用处理函数 |
preg_split |
将字符串切分为子串数组 |
preg_grep |
选择数组中能、不能由表达式匹配的元素 |
preg_quote |
转义字符串中的正则表达式元字符 |
搜索语法提取
$a = 'title!="powered by" && body="discuz" && host=="gov.cn" || title == "test" ';
$count = preg_match_all('/(?P<key>\w*)(?:\s*)(?P<op>==|!=|=)(?:\s*)(?:\")(?P<value>.*)(?:\")\s*/U', $or_str, $c);
匹配HTML标题
html源码中的标题,即获取<title>XXXXXX</title> 中的 xxxxxx
preg_match('/(?<=\<title\>)(?P<title>[^<]*)(?=\<\/title)/', $content, $match);
$title = array_get($match, 'title');匹配时间
匹配表示时刻的文字,例如 9.17 am
我的答案: [1-2]?[0-9]:[0-5][0-9] (?:a|p)m
标准答案: (1[0-2]|[1-9]):[0-5][0-9] (?:am|pm)
待匹配文本:
9:17 am
12:30 pm
43:88 pm
1:62 am
1:59 am匹配24小时制:
我的答案: ([01][0-9]|2[0-3]):[0-5][0-9]
标准答案: ([01]?[0-9]|2[0-3]):[0-5][0-9]