目录
- switch
- type
- 指针
- 结构体
- 结构体初始化
- 数组
- 数组切片
- Map
- select
- 并发
- channel
- 定义channel
- 单向channel
- 关闭channel
- channel 缓冲机制
- channel 超时机制
- channel的传递
- Mutex
- RWMutex
switch
switch type {
case 1:
return "a"
case 2:
return "a";
case 3:
return "b"
default:
return "c"
}type
- 定义结构体

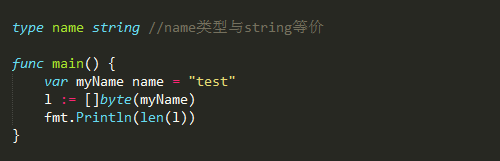
- 定义类型,相当于定义一个别名
- 定义接口类型

- 定义函数类型

指针
究其原因,是因为Go语言和C语言一样,类型都是基于值传递的。要想修改变量的值,只能传递指针。
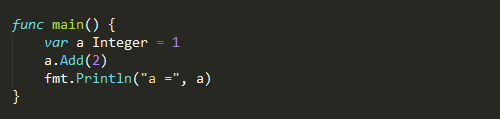
只有在你需要修改对象的时候,才必须用指针(这里使用 *a += b 是因为只有*a
的类型才是Integer,才能和b进行运算, 如果只是a 的话,a的类型是 *Integer)
结果是: a=3

如果你实现成员方法时传入的不是指针而是值(即传入Integer,而非*Integer),如下所示
结果是a=1,也就是维持原来的值

以下为示例代码:
type Person struct {
Name string
Age int
}
type Bird struct {
Color string
}
//为Person类创建walk方法
func (p *Person) walk() {
p.Name = "Anna"
fmt.Println(p.Name + " is walking")
}
//为bird类创建fly方法
func (b Bird) fly() {
b.Color = "yellow"
fmt.Println("a " + b.Color + " bird is flying")
}
func main() {
p := &Person{"Jason", 28}
p.walk()
fmt.Println(p.Name + " is walking")
b := &Bird{"red"}
b.fly()
fmt.Println("a " + b.Color + " bird is flying")
}
===============================
Anna is walking
Anna is walking
a yellow bird is flying
a red bird is flying
===============================
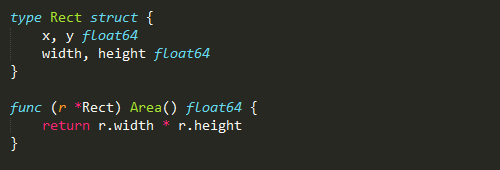
结构体
结构体(struct)和其他语言的类(class)有同等的地位
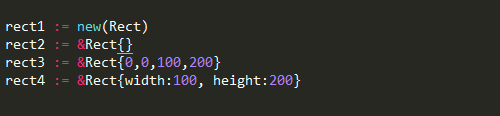
结构体初始化
未进行显式初始化的变量都会被初始化为该类型的零值,
例如bool类型的零
值为false, int类型的零值为0, string类型的零值为空字符串
数组
在Go语言中数组是一个值类型(value type)。
所有的值类型变量在赋值和作为参数传递时都将产生一次复制动作。
如果将数组作为函数的参数类型,则在函数调用时该参数将发生数据复制。
因此,在函数体中无法修改传入的数组的内容,因为函数内操作的只是所传入数组的一个副本。

数组切片
Go语言支持用myArray[first:last]这样的方式来基于数组生成一个数组切片
不包含first,包含last。index从1开始
a := "123456789"
DD(a[1:], a[2:3])
===============================
-val: 23456789
===============================
-val: 3
DD(a[1:], a[9:9], len(a))
===============================
type: string
#val: "23456789"
-val: 23456789
===============================
type: string
#val: ""
-val:
===============================
type: int
#val: 9
-val: 9
===============================
基于数组

直接创建

操作函数

cap()
函数返回的是数组切片分配的空间大小。

len()
函数返回的是数组切片中当前所存储的元素个数。

append()

第二个参数其实是一个不定参数,我们可以按自己需求添加若干个元素,
甚至直接将一个数组切片追加到另一个数组切片的末尾。

如果没有这个省略号的话,会有编译错误,因为按append()的语义,从第二个参数起的所有参数都是待附加的元素。因为mySlice中的元素类型为int,所以直接传递mySlice2是行不通的。加上省略号相
当于把mySlice2包含的所有元素打散后传入。
Map
Map 变量声明

Map 变量创建
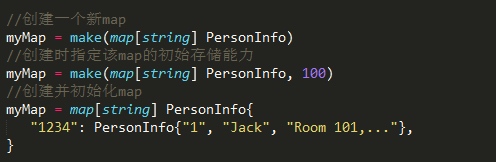
Map 元素赋值

Map 元素删除

Map 元素查找

Map 元素赋值的注意点
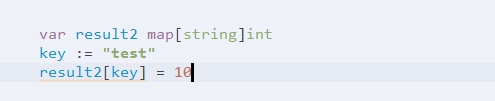
以上图中给result2赋值时出现的波浪线部分,提示

因为 var result2 map[string]int 只是申明了变量,但他没有初始化

采用 make(map[string]int) 的方式就可以避免这种风险
定义channel
channel是Go语言在语言级别提供的goroutine间的通信方式。 我们可以使用channel在两个或多个goroutine之间传递消息。
channel是类型相关的。也就是说,一个channel只能传递一种类型的值,这个类型需要在声 明channel时指定。如果对Unix管道有所了解的话,就不难理解channel,可以将其认为是一种类 型安全的管道。

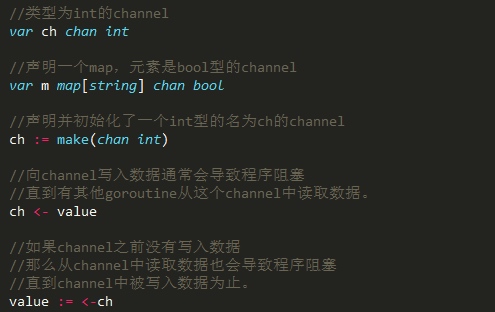
定义一个没有缓冲区的channel只有写入没有读取的话,程序直接锁死
c := make(chan int)
c<-1
helper.Dump(len(c))
===============================
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
===============================
正确代码如下:
c := make(chan int)
go func(c chan int) {
<-c
}(c)
c<-1
helper.Dump(len(c))
===============================
type: int
#val: 0
-val: <nil>
===============================如果定义了缓冲区则并不会报错,正常编译。代码如下:
c := make(chan int, 2)
c<-1
===============================
type: int
#val: 1
-val: <nil>
===============================
当写入超过缓冲区时,编译继续出错。代码如下:
c := make(chan int, 2)
c<-1
c<-1
c<-1
helper.Dump(len(c))
===============================
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
===============================
单向channel
channel本身必然是同时支持读写的,否则根本没法用。 假如一个channel真的只能读,那么肯定只会是空的,因为你没机会往里面写数据。 同理,如果一个channel只允许写,即使写进去了,也没有丝毫意义,因为没有机会读取里面 的数据。 所谓的单向channel概念,其实只是对channel的一种使用限制。

channel是一个原生类型,因此不仅支持被传递,还支持类型转换。 只有在介绍了单向channel的概念后,读者才会明白类型转换对于channel的意义:
就是在单向channel和双向channel之间进行转换。示例如下:

为什么要做这样的限制呢?从设计的角度考虑,所有的代码应该都遵循“最小权限原则”, 从而避免没必要地使用泛滥问题,进而导致程序失控。
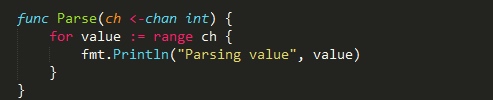
关闭channel

这个用法与map中的按键获取value的过程比较类似, 只需要看第二个bool返回值即可,如果返回值是false则表示ch已经被关闭。
select
select有比较多的限制,其中最大的一条限制就是每个case语句里必须是一个IO操作
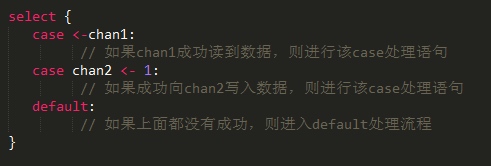
比如上面的例子中, 第一个case试图从chan1读取一个数据并直接忽略读到的数据, 而第二个case则是试图向chan2中写入一个整型数1,如果这两者都没有成功, 则到达default语句
并发
计算机的CPU从单内核(core)向多内核发展,而我们的程序都是串行的,计算机硬件的 能力没有得到发挥。 我们的程序因为IO操作被阻塞,整个程序处于停滞状态,其他IO无关的任务无法执行
并发能更客观地表现问题模型; 并发可以充分利用CPU核心的优势,提高程序的执行效率; 并发能充分利用CPU与其他硬件设备固有的异步性。
在一个函数调用前加上go关键字,这次调用就会在一个新的goroutine中并发执行。当被调用 的函数返回时,这个goroutine也自动结束了。需要注意的是,如果这个函数有返回值,那么这个 返回值会被丢弃

Go程序从初始化main package并执行main()函数开始,当main()函数返回时,程序退出, 且程序并不等待其他goroutine(非主goroutine)结束。 对于上面的例子,主函数启动了10个goroutine,然后返回,这时程序就退出了,而被启动的 执行Add(i, i)的goroutine没有来得及执行,所以程序没有任何输出。
Go语言提供的是另一种通信模型,即以消息机制而非共享内存(C共享内存是通过锁来控制争抢)作为通信方式。
channel
“不要通过共享内存来通信,而应该通过通信来共享内存。”
消息机制认为每个并发单元是自包含的、独立的个体,并且都有自己的变量,但在不同并发 单元间这些变量不共享。每个并发单元的输入和输出只有一种,那就是消息。这有点类似于进程 的概念,每个进程不会被其他进程打扰,它只做好自己的工作就可以了。不同进程间靠消息来通 信,它们不会共享内存。
channel是进程内的通信方式,因此通过channel传递对象的过程和调 用函数时的参数传递行为比较一致,比如也可以传递指针等。如果需要跨进程通信,我们建议用 分布式系统的方法来解决,比如使用Socket或者HTTP等通信协议。
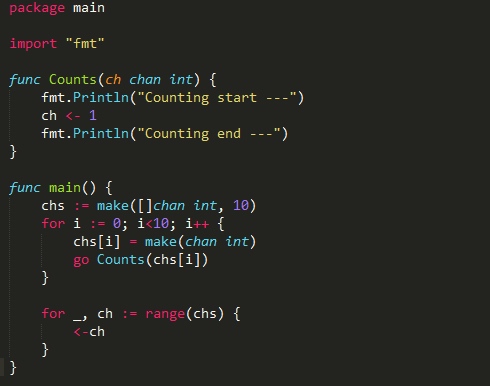
执行结果如下:
channel 缓冲机制

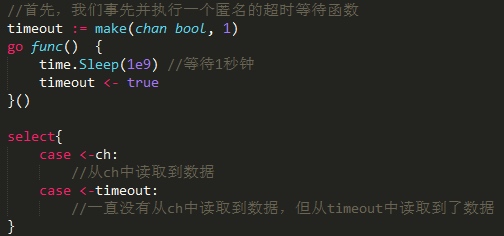
channel 超时机制
如下代码:

不出问题的话一切都正常运行。但如果出现了一个错误情况,即永远都没有人往ch里写数据,那 么上述这个读取动作也将永远无法从ch中读取到数据, 导致的结果就是整个goroutine永远阻塞并 没有挽回的机会。
channel的传递
-->管道的实现-->流式处理数据

多核并行化

Mutex
当一个goroutine获得了Mutex后,其他goroutine就只能乖乖等到这个goroutine释放该Mutex。
RWMutex
相对友好些,是经典的单写多读模型。 在读锁占用的情况下,会阻止写,但不阻止读,也就是多个goroutine可同时获取读锁(调用RLock()方法;) 而写锁(调用Lock()方法)会阻止任何其他goroutine(无论读和写)进来,整个锁相当于由该goroutine独占。 从RWMutex的实现看, RWMutex类型其实组合了Mutex:
全局唯一操作
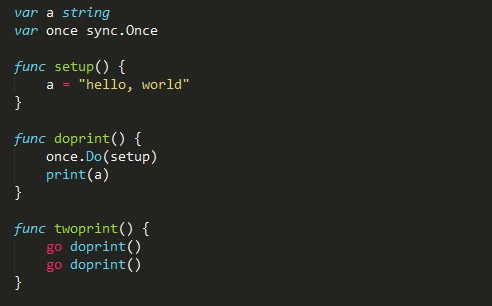
这段代码没有引入Once, setup()将会被每一个goroutine先调用一次,这至少对于这个 例子是多余的。
在现实中,我们也经常会遇到这样的情况。 Go语言标准库为我们引入了Once类型以解决这个问题。 once的Do()方法可以保证在全局范围内只调用指定的函数一次(这里指setup()函数), 而且所有其他goroutine在调用到此语句时,将会先被阻塞,直至全局唯一的once.Do()调用结束后才继续。