目录
- mysql的逻辑架构
- Innodb
- MyISAM
- 复制
- 锁
- 锁粒度
- ACID
- 隔离级别
- 存储引擎
- 聚簇索引
- 覆盖索引
- 索引扫描做排序
- 数据类型
- 整数类型
- 实数类型
- 字符串类型
- blob和text类型
- 枚举类型
- 日期类型
- 索引的优点
- b-tree索引适用类型
- 哈希索引
- 触发器
- 索引是否是最好的解决方案
- 高性能的索引策略
- 慢查询的经典案例
- 切分查询
- MySQL查询执行路径
- MySQL客户端和服务器之间的通信协议
- 查询状态
mysql的逻辑架构
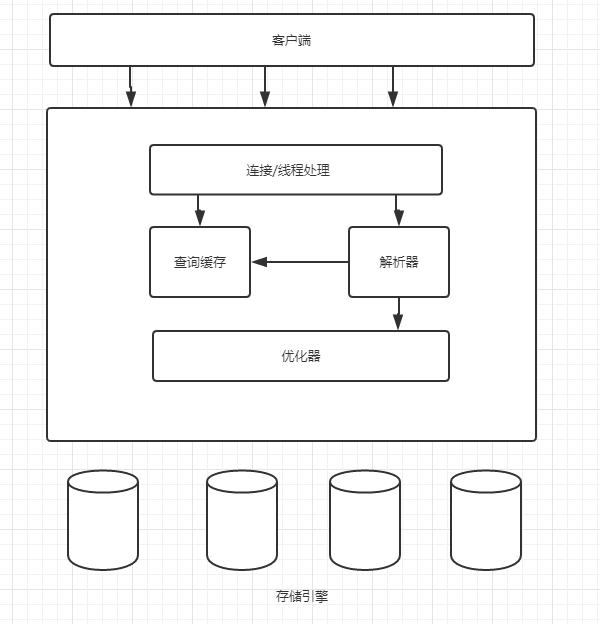
第一层: 连接处理、授权认证、安全
第二层: 大多的核心服务在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数,所有跨存储引擎的功能都在这一层实现(存储过程,触发器,视图等)
第三层: 存储引擎负责MySQL中数据的存储和提取
Innodb
基于聚簇索引建立的。对主键查询有很高的性能。不过它的二级索引(非主键索引)中必须包含主键列。所以如果主键列很大的话,其他所有索引都会很大。
MyISAM
支持全文索引,压缩,空间函数,但不支持事务和行级锁。崩溃后无法安全恢复。
数据文件(.MYD)和索引文件(.MYI)分开存储。可以存储行的记录数。
表锁,可以使用myisampack对MyISAM表进行压缩。能够提升查询性能,但不能对数据进行修改,支持索引但是只读。
复制
通常不会增加主库的开销,主要是启用二进制日志带来的开销。每个备库会对主库增加一些负载(列如网络IO开销,IO开销)
锁
- 读锁 共享锁
- 写锁 排他锁
- 死锁 两个或多个事务在同一资源上的占用
锁的各种操作 包括获得锁 、检查锁是否已经解除 、释放锁,都会增加系统的开销。
锁策略:就是在锁的开销和数据的安全性之间寻求平衡
每种MySQL存储引擎都可以实现自己的锁策略和锁粒度
锁粒度
- 表锁
- 行级锁
行级锁可以最大程度地支持并发处理,同时也带来了最大的锁开销(只在存储引擎层实现)
ACID
Aatomicity原子性Cconsistency一致性Iisolation隔离性(一个事务所做的修改在最终提交以前,对其他事务是不可见的)Ddurability持久性(事务提交 所做的修改会永久存储到数据库中)
隔离级别
每种存储引擎实现的隔离级别不同
脏读 (未提交读) (read uncommitted)
本次事务`没有提交`,所做修改对其他事务也`可见`。不可重复读 (提交读) (read commited)
本次事务`提交之前`,所做修改对其他事务`不可见`。同一个事务中同样的查询可能得到不一样的结果。可重复读(会导致幻读)(repeatable read)
在同一个事务里,SELECT的结果是事务开始时时间点的状态,同一个事务中`多次读取同样记录的结果是一致`的。 可串行化(serializable)
强制事务串行执行,避免了幻读。存储引擎
MySQL服务器层不管理事务,事务由下层的存储引擎实现。如果事务需要回滚,非事务型的表上的变更无法撤销,会导致数据库的不一致。除非万不得已建议不要混合使用多种存储引擎。InnoDB支持热备份。聚簇索引、空间占用较多、支持事务、支持在线热备份 、支持崩溃恢复MyISAM不支持事务和行级锁、崩溃后无法安全恢复 (在大数据量(3-5T)之间,如果采用MyISAM崩溃后的恢复就十分困难)- 不要轻易相信
MyISAM比InnoDB快之类的经验之谈这个结论往往不是绝对的。 - 在很多我们已知的场景中,
InnoDB的速度都可以让MyISAM望尘莫及,尤其是使用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
MyISAM 和 InnoDB 索引的区别(详见page:143)
MyISAM:
- 使用前缀压缩技术使得索引更小
- 通过数据的物理位置引用被索引的行
InnoDB:
- 按照原数据格式进行存储
- 根据主键引用被索引的行(使用Innodb时应该尽可能按主键顺序插入数据,并且尽可能使用单调增加的聚簇键的值来插入新行)
聚簇索引
术语聚簇表示数据行和相邻的键值紧凑地存储在一起。 详细参见文章:聚簇索引和非聚簇索引的区别
覆盖索引
一个索引包含所有需要查询的字段的值就是覆盖索引,MySQL只能使用btree索引做覆盖索引。InnoDB的二级索引在叶子节点中保存了行的主键值,如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询。
当发起一个被索引覆盖的时,在EXPLAIN的Extra列可以看到Using index的信息。例如:
inventory有个多列索引 (store_id,film_id)。如果只需访问这两列,就可以使用这个索引做覆盖索引。
select stire_id, film_id from inventory
索引扫描做排序
表rental中有索引(rental_date,inventory_id,customer_id)。MySQL可以使用这个索引为一下查询做排序
select rental_id, staff_id from rental
where rental_date = '2005-05-25'
order by inventory_id, customer_id
即使order by子句不满足索引的最左前缀的要求,也可以用于查询排序,这是因为索引的第一列被指定为一个常数。
还有更多可以使用索引做排序的查询示例。
下面这个查询可以利用索引排序,是因为查询为索引的第一列提供了常量条件,而使用第二列进行排序,将两列组合在一起,就形成了索引的最左前缀。
where retal_date = '2015-05-25' order by inventory_id
下面这个查询也没问题,因为 order by 使用的两列就是索引的最左前缀
where retal_date > '2015-05-25' order by rental_date, inventory_id以下是不能使用索引做排序的查询:
#使用了两种不同的排序方向,但是索引列都是正序排序的:
`where rental_date = '2005-05-25' order by inventory_id desc , customer_id asc`
#order by 子句中应用了一个不在索引中的列
`where rental_date = '2005-05-25' order by inventory_id, staff_id`
#where 和 order by 中的列无法组合成索引最左前缀
`where rental_date = '2005-05-25' order by customer_id`
#第一列上是范围条件,所以无法使用索引的其余列
`where rental_date > '2005-05-25' order by inventory_id, customer_id`
#在inventory_id列上有多个等于条件,对于排序来说,也是一种范围查询
`where rental_date = '2005-05-25' and inventory_id IN (1,2) order by customer_id`
数据类型
整数类型
整数类型范围计算方式-2^(N-1) ~ 2^(N-1)-1
| -- | -- |
|---|---|
| tinyint | 8位 |
| smallint | 16位 |
| mediumint | 24位 |
| int | 32位 |
| bigint | 64位 |
Mysql可以为整数类型指定宽度列如init(11)对大多数应用没有意义。它不会限制值得合法范围,只是规定了MySQL的交互工具(例如MySQL命令行客户端)用来显示字符的个数。对于存储和计算来说 int(1) 和 int(20) 是相同的。
实数类型
带有小数部分的数字
float4字节double8字节decimal每4个字节存9个数字
decimal(18,9) 一共使用9个字节:小数点前4个字节、小数点后4个字节、小数点本身1个字节
(18,9)中的9表示小数点右边存储9个数字,用于存储精确的小数,支持精确计算。
字符串类型
varchar仅使用必要的空间char定长
blob和text类型
二进制和字符方式存储
tinyblob smallblob blob mediumblob longblob
tinytext smalltext text mediumtext longtext当blob和text值太大时,会使用专门的外部存储区域来进行存储。此时每个值在行内需要1-4个字节存储一个指针,然后在外部区域存储实际的值。
枚举(ENUM)
使用枚举代替常用的字符串类型,实际数据库存储的为整数而不是字符串,所以避免枚举整数。 且排序是按照内部存储的整数进行排序,而不是字符串进行排序。
劣势:和char、varchar 关联时比直接使用char、varchar之间的关联更慢
日期和时间类型
优先使用
datetime
datetime1001-9999年 与时区无关timestamp1970-2038 时区与服务器 操作系统 有关
索引的优点
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机io变为顺序io
b-tree索引适用类型以及限制
page:145
b-tree 意味着所有的值都是按顺序存储的,所以对于范围查找很适合.
限制:
- 不是按照索引的最左列则无法使用索引
- 不能跳过索引中的列
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引查找
哈希索引
什么是哈希索引,哈希索引的弊端?
只有精确匹配索引所有列的查询才有效,mysql中只有memory引擎支持hash索引。hash索引只存储对应的哈希值和行指针,而不存储字段值。 因为索引自身只需存储对应的哈希值,所以索引的结构十分紧凑。
- 不存储字段值,所以不能使用索引中的值来避免读取行
- 并不是按照索引值顺序存储,所以无法用于排序
- 不支持部分索引匹配查找 如在数据列(A,B)上建立哈希索引 如果查询只有数据列A则无法使用该索引
- 只支持等值比较查询
- 哈希冲突带来的索引维护代价
什么是触发器
模拟innodb 创建自定义哈希索引 CRC32 触发器,触发器语句(page:149)
create table pseudohash(
id int unsigned not null auto_increment,
url varchar(255) not null,
url_crc int unsigned not null default 0,
primary key(id)
);
delimiter //
create trigger pseudohash_crc_ins before insert on pseudohash for each row begin set new.url_crc=crc32(new.url);
end;
//
create trigger pseudohash_crc_upd before update on pseudohash for each row begin set new.url_crc=crc32(new.url);
end;
//
delimiter;
索引是否是最好的解决方案
(page:152)
索引并不总是最好的解决方案,
只有当索引带来的好处大于带来的额外工作时才是有效的。
非常小的表大部分情况下简单的全表扫描才更有效,
中大型的表索引就非常有效,
特大型的表索引就不如分区技术来的有效。
高性能的索引策略
独立的列, 前缀索引和索引选择性,多列索引, 选择合适的索引列顺序
- 独立的列:索引列不能是表达式的一部分
- 多列索引:在所有的字段上面都单独添加索引的话,查询时mysql会进行索引合并优化(
Using union (primary,idx_fk_film_id); Using where)。但索引合并并没有单个索引来的有效率。索引合并策略有时候是一种优化的结果实际上说明了索引建的不好,建一个包含相关列的多列索引比较好。 - 合适的索引列顺序:
where子句中的排序、分组和范围条件都要考虑 - 前缀索引
- 根据列的选择性来决定索引的顺序
- 如果一个索引包含所有需要查询的字段的值就称为覆盖索引 覆盖索引必须要存储索引列的值,所以MySQL只能使用btree索引做覆盖索引
- 分析多余和重复的索引的工具 (187)
- 根据选择性和使用频率尽量将范围查询的列放到索引后面
- 通过in覆盖不在where子句中的列
维护索引和表
show index from orders
check table orders
show table status 延迟关联
select <cols> from profiles inner join
(
select <primary key cols> from profiles
where x.sex='M'
order by rating
limit 100000,10
) as x
using (<primart key cols>)如果发现查询需要扫描大量的数据但只返回少数行 以下方法优化
- 使用索引覆盖扫描(把所有需要用的列都放到索引中)
- 改变库的表结构 (如使用汇总表)
- 重写复杂查询 切分查询 分解关联查询(更好的利用缓存、减少锁的竞争、在应用层做关联、使用IN代替关联 可能比随机的关联更高效)
- 查询状态
SHOW FULL PROCESSLIST - IN操作同样很快
- 在很多数据库系统中 IN完全等同于多个OR条件的子句,因为这两者是完全等价的。 在
Mysql中不成立 - Mysql将IN列表中的数据先进行排序 然后通过二分查找的方式确定列表中的值是否满足条件 这是一个
O(log n)复杂度的操作 - 等价的转换成OR查询那么复杂度为
O(n) - 对于IN列表中有大量取值的时候 MYsql的处理速度将会更快
- 在很多数据库系统中 IN完全等同于多个OR条件的子句,因为这两者是完全等价的。 在
count() 作用
- 一个容易产生的误解就是
MyISAM的count()函数总是非常快,不过这是有前提条件的,只有没有任何where条件的count(*)才会非常快。 - 因为此时无需实际的去计算表的行数。当统计带where子句的结果集行数,那么
MyISAM和其他存储引擎没有任何不同。 - 如果只是希望知道结果集的行数最好使用
count(*)这样写意义清晰,性能也会很好。 count()的括号中制定了列或者列的表达式,则统计的就是这个表达式有值得结果数(而不是NULL)。count(*)通配符*并不会像猜想的那样扩展成所有的列,而是忽略所有的列而直接统计所有的行数。
慢查询的经典案例
- 查询不需要的数据解决方法是
limit或只获取需要的字段。 - 多表关联时返回全部的列。
- 总是取出全部的列,取出全部的列肯定是无法覆盖索引的。
- 重复查询相同的数据:解决方法
缓存。
切分查询
关于切分查询,删除旧的数据就是一个很好的例子,定期的清楚大量数据时,如果用一个大的语句一次性完成的话,
则可能需要一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
例如将一个大的DELETE语句切分成多个较小的查询能够尽可能小地影响Mysql性能,同时还可以减少MySQL复制的延迟。
如果每次删除数据后,都暂停一会再做下次删除,这样也可以将服务器上原本一次性的压力分散到一个很长时间段中,可以降低服务器的影响。
MySQL查询执行路径

MySQL客户端和服务器之间的通信协议
客户端和服务器之间的通信协议是半双工的
- 要么服务器向客户端发送数据
- 要么客户端向服务器发送数据
这两个动作不能同时,发生明显的限制是:
一旦一端开始发送消息,另一端要接受完整个消息才能响应它,这意味着没办法进行流量控制。
查询状态
查看当前正在进行的进程,对于有锁表等情况的排查很有用处 。
SHOW PROCESSLIST; 默认显示前100条
SHOW FULL PROCESSLIST; 显示所有

| command | desc |
|---|---|
| sleep | 线程正在等待客户端发送新的请求 |
| query | 线程正在执行查询或正在将结果发送给客户端 |
| locked | 线程正在等待表锁,innodb的行锁并不会体现在线程状态中 |
| analyzing and statistics | 线程正在收集存储引擎的统计信息,并生成查询的执行计划 |
| copying to tmp table [on disk] | 线程正在执行查询,并且将其结果集都复制到一个临时表中,这种状态一般要么是在做group by,要么文件排序操作,或是union操作 |
| sorting result | 线程正在对结果集进行排序 |
| sending data | 线程可能在多个状态直接传送数据,或生成结果集,或者在向客户端返回数据 |