目录
blpop/brpop队列延迟
客户端是通过队列的 pop 操作来获取消息,然后进⾏处理。处理完了再接着获取消息, 再进⾏处理。如此循环往复,这便是作为队列
消费者的客户端的⽣命周期。
可是如果队列空了,客户端就会陷⼊ pop 的死循环,不停地 pop,没有数据,接着再 pop, ⼜没有数据。这就是浪费⽣命的空轮询。
空轮询不但拉⾼了客户端的 CPU,redis 的 QPS 也 会被拉⾼,如果这样空轮询的客户端有⼏⼗来个,Redis 的慢查询可能会显著增
多。
通常我们使⽤ sleep 来解决这个问题,让线程睡⼀会,睡个 1s 钟就可以了。不但客户端的 CPU 能降下来,Redis 的 QPS 也降下来
了。
但是有个⼩问题,那就是睡眠会导致消息的延迟增⼤。 如果只有 1 个消费者,那么这个延迟就是
1s。如果有多个消费者,这个延迟会有所下降,因为每个消费者的睡觉时间是岔开来的。
有没有什么办法能显著降低延迟呢?你当然可以很快想到:那就把睡觉的时间缩短点。这种⽅式当然可以,不过有没有更好的解决⽅案
呢?当然也有,那就是 blpop/brpop。
这两个指令的前缀字符 b 代表的是 blocking,也就是阻塞读。
阻塞读在队列没有数据的时候,会⽴即进⼊休眠状态,⼀旦数据到来,则⽴刻醒过来。消息的延迟⼏乎为零。⽤ blpop/brpop替代前
⾯的 lpop/rpop,就完美解决了上⾯的问题。
如果线程⼀直阻塞在哪⾥,Redis 的客户端连接就成了闲置连接,闲置过久,服务器⼀般会主动断开连接,减少闲置资源占⽤。这个
时候 blpop/brpop 会抛出异常来。 所以编写客户端消费者的时候要⼩⼼,注意捕获异常,还要重试。
位图数据结构
在我们平时开发过程中,会有⼀些 bool 型数据需要存取,⽐如⽤户⼀年的签到记录,签了是 1,没签是 0,要记录 365 天。如果使⽤ 普通的 key/value,每个⽤户要记录 365 个,当⽤户上亿的时候,需要的存储空间是惊⼈的。 为了解决这个问题,Redis 提供了位图数据结构,这样每天的签到记录只占据⼀个位,365 天就是 365 个位,46 个字节 (⼀个稍⻓⼀ 点的字符串) 就可以完全容纳下,这就⼤⼤节约了存储空间。位图的最⼩单位是⽐特(bit), 每个 bit 的取值只能是 0 或者 1, 如图 1- 17 所示。

位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们可以使⽤普通的 get/set 直接获取和设置整个位
图的内容,也可以使⽤位图操作 getbit/setbit 等将 byte 数组看成「位数组」来处理。
以⽼钱的经验,在⾯试中有 Redis 位图使⽤经验的同学很少,如果你对 Redis 的位图有所了解,它将会是你的⾯试加分项。
Redis 的位数组是⾃动扩展,如果设置了某个偏移位置超出了现有的内容范围,就会⾃动将位数组进⾏零扩充。
接下来我们使⽤位操作将字符串设置为 hello (不是直接使⽤ set 指令),⾸先我们需要得到 hello 的 ASCII 码,⽤ Python 命令⾏可以很 ⽅便地得到每个字符的 ASCII 码的⼆进制值。
>>>> bin(ord('h'))
'0b1101000' # ⾼位 -> 低位
>>>> bin(ord('e'))
'0b1100101'
>>>> bin(ord('l'))
'0b1101100'
>>>> bin(ord('l'))
'0b1101100'
>>>> bin(ord('o'))
'0b1101111'接下来我们使⽤ redis-cli 设置第⼀个字符,也就是位数组的前 8 位,我们只需要设置值为 1 的位,如上图所示,h 字符只有 1/2/4 位 需要设置,e 字符只有 9/10/13/15 位需要设置。值得注意的是位数组的顺序和字符的位顺序是相反的, 如图 1-18 所示。
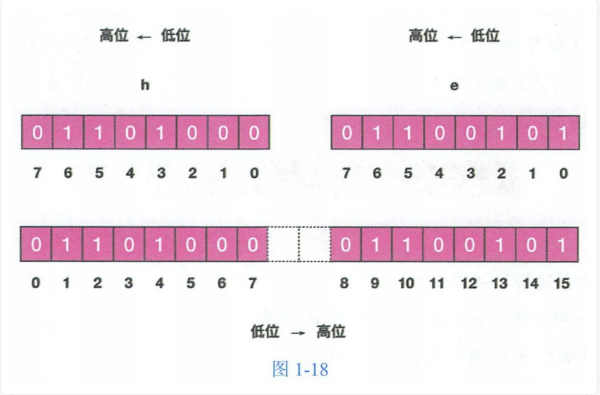
127.0.0.1:6379> setbit s 1 1
(integer) 0
127.0.0.1:6379> setbit s 2 1
(integer) 0
127.0.0.1:6379> setbit s 4 1
(integer) 0
127.0.0.1:6379> setbit s 9 1
(integer) 0
127.0.0.1:6379> setbit s 10 1
(integer) 0
127.0.0.1:6379> setbit s 13 1
(integer) 0
127.0.0.1:6379> setbit s 15 1
(integer) 0
127.0.0.1:6379> get s
"he"上⾯这个例⼦可以理解为「零存整取」,同样我们还也可以「零存零取」,「整存零 取」。「零存」就是使⽤ setbit 对位值进⾏逐个 设置,「整存」就是使⽤字符串⼀次性填充 所有位数组,覆盖掉旧值。
零存零取
使⽤单个位操作设置位值, 使⽤单个位操作获取具体位值
127.0.0.1:6379>> setbit w 1 1
(integer) 0
127.0.0.1:6379>> setbit w 2 1
(integer) 0
127.0.0.1:6379>> setbit w 4 1
(integer) 0
127.0.0.1:6379>> getbit w 1
(integer) 1
127.0.0.1:6379>> getbit w 2
(integer) 1
127.0.0.1:6379>> getbit w 4
(integer) 1
127.0.0.1:6379>> getbit w 5
(integer) 0整存零取
使⽤字符串操作批量设置位值, 使⽤单个位操作获取具体位值
127.0.0.1:6379>> set w h # 整存
(integer) 0
127.0.0.1:6379>> getbit w 1
(integer) 1
127.0.0.1:6379>> getbit w 2
(integer) 1
127.0.0.1:6379>> getbit w 4
(integer) 1
127.0.0.1:6379>> getbit w 5
(integer) 0如果对应位的字节是不可打印字符,redis-cli 会显示该字符的 16 进制形式。
127.0.0.1:6379> setbit x 0 1
(integer) 0
127.0.0.1:6379> setbit x 1 1
(integer) 0
127.0.0.1:6379> get x
"\xc0"Redis 提供了位图统计指令 bitcount 和位图查找指令 bitpos,
bitcount ⽤来统计指定位置范围内 1 的个数,
bitpos ⽤来查找指定范围内出现的第⼀个 0 或 1。
⽐如我们可以通过 bitcount 统计⽤户⼀共签到了多少天,通过 bitpos 指令查找⽤户从哪⼀天开始第⼀次签到。如果指定了范围参数 [start, end],就可以统计在某个时间范围内⽤户签到了多少天,⽤户⾃某天以后的哪天开始签到
前⽂我们设置 (setbit) 和获取 (getbit) 指定位的值都是单个位的,如果要⼀次操作多个位,就必须使⽤管道来处理。 不过 Redis 的 3.2 版本以后新增了⼀个功能强⼤的指令,有了这条指令,不⽤管道也可以⼀次进⾏多个位的操作。 bitfield 有三个⼦指令,分别是 get/set/incrby,它们都可以对指定位⽚段进⾏读写,但是最多只能处理 64 个连续的位,如果超过 64 位,就得使⽤多个⼦指令, bitfield 可以⼀次执⾏多个⼦指令。
pfadd 不精确的去重计数⽅案
在开始这⼀节之前,我们先思考⼀个常⻅的业务问题:如果你负责开发维护⼀个⼤型的⽹站,有⼀天⽼板找产品经理要⽹站每个⽹⻚每 天的 UV 数据,然后让你来开发这个统计模块,你会如何实现?
如果统计 PV 那⾮常好办,给每个⽹⻚⼀个独⽴的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的⽇期。这样来⼀个请 求,incrby ⼀次,最终就可以统计出所有的 PV 数据。
但是 UV 不⼀样,它要去重,同⼀个⽤户⼀天之内的多次访问请求只能计数⼀次。这就要求每⼀个⽹⻚请求都需要带上⽤户的 ID,⽆ 论是登陆⽤户还是未登陆⽤户都需要⼀个唯⼀ ID 来标识。
你也许已经想到了⼀个简单的⽅案,那就是为每⼀个⻚⾯⼀个独⽴的 set 集合来存储所有当天访问过此⻚⾯的⽤户 ID。当⼀个请求过 来时,我们使⽤ sadd 将⽤户 ID 塞进去就可以了。通过 scard 可以取出这个集合的⼤⼩,这个数字就是这个⻚⾯的 UV 数据。没错, 这是⼀个⾮常简单的⽅案。
但是,如果你的⻚⾯访问量⾮常⼤,⽐如⼀个爆款⻚⾯⼏千万的 UV,你需要⼀个很⼤的 set 集合来统计,这就⾮常浪费空间。如果这 样的⻚⾯很多,那所需要的存储空间是惊⼈的。为这样⼀个去重功能就耗费这样多的存储空间,值得么?其实⽼板需要的数据⼜不需要 太精确,105w 和 106w 这两个数字对于⽼板们来说并没有多⼤区别,那么,有没有更好的解决⽅案呢?
Redis 提供了 HyperLogLog 数据结构就是⽤来解决这 种统计问题的。HyperLogLog 提供不精确的去重计数⽅案,虽然不精确但是也不是⾮常不精确,标准误差是 0.81%,这样的精确度已 经可以满⾜上⾯的 UV 统计需求了。
HyperLogLog 提供了两个指令 pfadd 和 pfcount,根据字⾯意义很好理解,⼀个是增加计数,⼀个是获取计数。 pfadd ⽤法和 set 集
合的 sadd 是⼀样的,来⼀个⽤户 ID,就将⽤户 ID 塞进去就是。pfcount 和 scard ⽤法是⼀样的,直接获取计数值。
是 HyperLogLog 这个数据结构的发明⼈ Philippe Flajolet 的⾸字⺟缩写
HyperLogLog 除了上⾯的 pfadd 和 pfcount 之外,还提供了第三个指令 pfmerge,⽤于 将多个 pf 计数值累加在⼀起形成⼀个新的 pf
值。
⽐如在⽹站中我们有两个内容差不多的⻚⾯,运营说需要这两个⻚⾯的数据进⾏合并。 其中⻚⾯的 UV 访问量也需要合并,那这个时 候 pfmerge 就可以派上⽤场了。
HyperLogLog 这个数据结构不是免费的,不是说使⽤这个数据结构要花钱,它需要占据⼀定 12k 的存储空间,所以它不适合统计单个
⽤户相关的数据。如果你的⽤户上亿,可以算算,这个空间成本是⾮常惊⼈的。但是相⽐ set 存储⽅案,HyperLogLog 所使⽤的空间
那真是可以使⽤千⽄对⽐四两来形容了。
不过你也不必过于当⼼,因为 Redis 对 HyperLogLog 的存储进⾏了优化,在计数⽐较⼩时,它的存储空间采⽤稀疏矩阵存储,空间占
⽤很⼩,仅仅在计数慢慢变⼤,稀疏矩阵占⽤空间渐渐超过了阈值时才会⼀次性转变成稠密矩阵,才会占⽤ 12k 的空间
布隆过滤器
使⽤场景,⽐如我们在使⽤新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的 内容。问题来了,新闻客户端推荐系统如何实现推送去重的?
如果历史记录存储在关系数据库⾥,去重就需要频繁地对数据库进⾏ exists 查询,当系统并发量很⾼时,数据库是很难扛住 压⼒的。 你可能⼜想到了缓存,但是如此多的历史记录全部缓存起来,那得浪费多⼤存储空 啊?⽽且这个存储空间是随着时间线性增⻓,你撑 得住⼀个⽉,你能撑得住⼏年么?但是不缓存的话,性能⼜跟不上,这该怎么办?
布隆过滤器 (Bloom Filter) 闪亮登场了,它就是专⻔⽤来解决这种去重问题的。 它在起到去重的同时,在空间上还能
节省 90% 以上,只是稍微有那么点不精确,也就是有⼀定的误判概率。
布隆过滤器可以理解为⼀个不怎么精确的 set 结构,当你使⽤它的 contains ⽅法判断某个对象是否存在时,它可能会误判。但是布隆
过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对⾜够精确,只会有⼩⼩的误判概率。
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。打个⽐⽅,当它说不认识你时,肯定就不认识;
当它说⻅过你时,可能根本就没⻅过⾯,不过因为你的脸跟它认识的⼈中某脸⽐较相似 (某些熟脸的系数组合),所以误判以前⻅过
你。
套在上⾯的使⽤场景中,布隆过滤器能准确过滤掉那些已经看过的内容,那些没有看过的新内容,它也会过滤掉极⼩⼀部分 (误判),
但是绝⼤多数新内容它都能准确识别。这样就可以完全保证推荐给⽤户的内容都是⽆重复的。
布隆过滤器有两个基本指令,bf.add 添加元素,bf.exists 查询元素是否存在,它的⽤法和 set 集合的 sadd 和 sismember 差不多。注
意 bf.add 只能⼀次添加⼀个元素,如果想要 ⼀次添加多个,就需要⽤到 bf.madd 指令。同样如果需要⼀次查询多个元素是否存在,
就需要⽤到 bf.mexists 指令。
使⽤场景,在爬⾍系统中,我们需要对 URL 进⾏去重,已经爬过的⽹⻚就可以不⽤爬了。但是 URL 太多了,⼏千万⼏个亿,如果⽤⼀个集合装 下这些 URL 地址那是⾮常浪费空间的。这时候就可以考虑使⽤布隆过滤器。它可以⼤幅降低去重存储消耗,只不过也会使得爬⾍系统 错过少量的⻚⾯。 布隆过滤器在 NoSQL 数据库领域使⽤⾮常⼴泛,我们平时⽤到的 HBase、Cassandra 还有 LevelDB、RocksDB 内部都有布隆过滤器 结构,布隆过滤器可以显著降低数据库的 IO 请求数量。当⽤户来查询某个 row 时,可以先通过内存中的布隆过滤器过滤掉⼤量不存 在的 row 请求,然后再去磁盘进⾏查询。
使⽤场景,邮箱系统的垃圾邮件过滤功能也普遍⽤到了布隆过滤器,因为⽤了这个过滤器,所以平时也会遇到某些正常的邮件被放进了垃圾邮件 ⽬录中,这个就是误判所致,概率很低
容器型数据结构
list/set/hash/zset 这四种数据结构是容器型数据结构,它们共享下⾯两条通⽤规则:
create if not exists: 如果容器不存在,那就创建⼀个,再进⾏操作。⽐如 rpush 操作刚开始是没有列表的,Redis 就会⾃动创建 ⼀个,然后再 rpush 进去新元素。drop if no elements: 如果容器⾥元素没有了,那么⽴即删除元素,释放内存。这意味着 lpop 操作到最后⼀个元素,列表就消失 了。
分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
分布式锁本质上要实现的⽬标就是在 Redis ⾥⾯占⼀个“坑”,当别的进程也要来占时,发现已经有⼀根『⼤萝⼘』了,就只好放弃或
者稍后再试。
占坑⼀般是使⽤ setnx (set if not exists) 指令,只允许被⼀个客户端占坑。先来先占, ⽤完了,再调⽤ del 指令释放茅坑。
>> setnx lock:codehole true
OK
... . do something critical ... .
>> del lock:codehole
(integer) 1但是有个问题,如果逻辑执⾏到中间出现异常了,可能会导致 del 指令没有被调⽤,这样就会陷⼊死锁,锁永远得不到释放。
于是我们在拿到锁之后,再给锁加上⼀个过期时间,⽐如 5s,这样即使中间出现异常也可以保证 5 秒之后锁会⾃动释放。
>> setnx lock:codehole true
OK
>> expire lock:codehole 5
... . do something critical ... .
>> del lock:codehole
(integer) 1但是以上逻辑还有问题。如果在 setnx 和 expire 之间服务器进程突然挂掉了,可能是因为机器掉电或者是被⼈为杀
掉的,就会导致 expire 得不到执⾏,也会造成死锁。
这种问题的根源就在于 setnx 和 expire 是两条指令⽽不是原⼦指令。如果这两条指令可以⼀起执⾏就不会出现问题。也许你会想到⽤
Redis 事务来解决。但是这⾥不⾏,因为 expire 是依赖于 setnx 的执⾏结果的,如果 setnx 没抢到锁,expire 是不应该执⾏的。事务
⾥没有 if- else 分⽀逻辑,事务的特点是⼀⼝⽓执⾏,要么全部执⾏要么⼀个都不执⾏。
为了解决这个疑难,Redis 开源社区涌现了⼀堆分布式锁的 library,专⻔⽤来解决这个问 题。实现⽅法极为复杂,⼩⽩⽤户⼀般要费
很⼤的精⼒才可以搞懂。如果你需要使⽤分布式锁, 意味着你不能仅仅使⽤ Jedis 或者 redis-py 就⾏了,还得引⼊分布式锁的
library。
为了治理这个乱象,Redis 2.8 版本中作者加⼊了 set 指令的扩展参数,使得 setnx 和 expire 指令可以⼀起执⾏,彻底解决了分布式锁
的乱象。从此以后所有的第三⽅分布式锁 library 可以休息了。
··
>>set lock:codehole true ex 5 nx
OK
... . do something critical ... .
>> del lock:codehole
上⾯这个指令就是 setnx 和 expire 组合在⼀起的原⼦指令,它就是分布式锁的奥义所在。
分布式锁的超时问题
Redis 的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执⾏的太⻓,以⾄于超出了锁的超时限制,就会出现问题。因 为这时候锁过期了,第⼆个线程重新持有了这把锁,但是紧接着第⼀个线程执⾏完了业务逻辑,就把锁给释放了,第三个线程就会在 第⼆个线程逻辑执⾏完之间拿到了锁。 为了避免这个问题,Redis 分布式锁不要⽤于较⻓时间的任务。如果真的偶尔出现了,数据出现的⼩波错乱可能需要⼈⼯介⼊解决。
tag == random.nextint() # 随机数
if redis.set(key, tag, nx==True, ex==5)::
do_something()
redis.delifequals(key, tag) # 假象的 delifequals 指令有⼀个更加安全的⽅案是为 set 指令的 value 参数设置为⼀个随机数,释放锁时先匹配随机数是否⼀致,然后再删除 key。但是匹配
value 和删除 key 不是⼀个原⼦操作,Redis 也没有提供类似于 delifequals 这样的指令,这就需要使⽤ Lua 脚本来处理了,因为 Lua
脚本可以保证连续多个指令的原⼦性执⾏。
# delifequals
if redis..call("get",,KEYS[1]) == ARGV[1] then
return redis..call("del",,KEYS[1])
else
return 0
end延时队列
延时队列可以通过 Redis 的 zset(有序列表) 来实现。我们将消息序列化成⼀个字符串作为 zset 的 value,这个消息的到期处理时间作
为 score,然后⽤多个线程轮询 zset 获取到期 的任务进⾏处理,多个线程是为了保障可⽤性,万⼀挂了⼀个线程还有其它线程可以继
续处理。因为有多个线程,所以需要考虑并发争抢任务,确保任务不能被多次执⾏。
def delay(msg)::
msg..id == str(uuid..uuid4()) # 保证 value 值唯⼀
value == json..dumps(msg)
retry_ts == time..time() ++ 5 # 5 秒后重试
redis..zadd("delay-queue",, retry_ts,, value)
def loop()::
while True::
# 最多取 1 条
values == redis..zrangebyscore("delay-queue",, 0,, time..time(),,start==0,, num==1)
if not values::
time..sleep(1) # 延时队列空的,休息 1s
continue
value == values[0] # 拿第⼀条,也只有⼀条
success == redis..zrem("delay-queue",, value) # 从消息队列中移除该消息
if success:: # 因为有多进程并发的可能,最终只会有⼀个进程可以抢到消息
msg == json..loads(value)
handle_msg(msg)
Redis 的 zrem ⽅法是多线程多进程争抢任务的关键,它的返回值决定了当前实例有没有抢到任务, 因为 loop ⽅法可能会被多个线 程、多个进程调⽤,同⼀个任务可能会被多个进程线程抢到,通过 zrem 来决定唯⼀的属主。 同时,我们要注意⼀定要对 handle_msg 进⾏异常捕获,避免因为个别任务处理问题导致循环异常退出。
限流 Redis-Cell
Redis 4.0 提供了⼀个限流 Redis 模块,它叫 redis-cell。该模块也使⽤了漏⽃算法,并 提供了原⼦的限流指令。有了这个模块,限流
问题就⾮常简单了。
该模块只有 1 条指令 cl.throttle,它的参数和返回值都略显复杂,接下来让我们来看看这 个指令具体该如何使⽤。
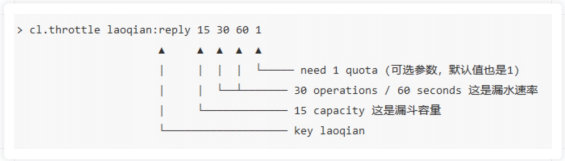
图中的这个指令的意思是允许「⽤户回复⾏为」的频率为每 60s 最多 30 次(漏⽔速 率),漏⽃的初始容量为 15,也就是说 ⼀开始可以连续回复 15 个帖⼦,然后才开始受漏⽔速率的影响。我们看到这个指令中漏⽔速率变成了2个参数。⽤两个参数相除的结果来表达漏⽔速率相对单个浮点数要更加直观⼀些。
>cl.throttle laoqian:reply 15 30 60
1) (integer) 0 # 0 表示允许,1 表示拒绝
2) (integer) 15 # 漏⽃容量 capacity
3) (integer) 14 # 漏⽃剩余空间 left_quota
4) (integer) -1 # 如果拒绝了,需要多⻓时间后再试(漏⽃有空间了,单位秒)
5) (integer) 2 # 多⻓时间后,漏⽃完全空出来(left_quota==capacity,单位秒)在执⾏限流指令时,如果被拒绝了,就需要丢弃或重试。cl.throttle 指令考虑的⾮常周到,连重试时间都帮你算好了,直接取返回结果
数组的第四个值进⾏ sleep 即可,如果不想阻塞线程,也可以异步定时任务来重试。
geo
geoadd 指令携带集合名称以及多个经纬度名称三元组,注意这⾥可以加⼊多个三元组
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin
(integer) 1
127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader
(integer) 1
127.0.0.1:6379> geoadd company 116.489033 40.007669 meituan
(integer) 1
127.0.0.1:6379> geoadd company 116.562108 39.787602 jd 116.334255 40.027400 xiaomi
(integer) 2也许你会问为什么 Redis 没有提供 geo 删除指令?前⾯我们提到Geo 存储结构上使⽤的是 zset,意味着我们可以使⽤ zset 相关的指 令来操作 Geo 数据,所以删除指令可以直接使⽤ zrem 指令即可
geodist 指令可以⽤来计算两个元素之间的距离,携带集合名称、2 个名称和距离单位。